


💥DeepSeek Just Killed AI Stocks Today. What Now?💥
Capitulating or buying the dip?

If you have enjoyed reading this article, please consider liking, restacking, or sharing with your friends! Your engagement is the biggest support. ❤️
Today we are discussing DeepSeek and What to Do with AI stocks post the sell-off (NVDA down a massive 17%).

Back in December last year, I shared my concerns that a potential AI capex slowdown could lead to stock sell off in my NVDA note and AVGO primer (published here and here). I also laid out my valuation framework and recommended selling AVGO at $140 (which was exactly the peak price last week). If AVGO investors had read the note and trimmed position last week, they would have avoided the significant losses today!
As a former hedge fund investor, I share detailed valuation framework and entry/exit price to help you maximize upside potential and minimize downside risk.
SUBSCRIBE BELOW so you don’t miss the timely and in-depth stock analysis!
💥Now let’s dive into it! Today we are going to discuss 💥
Quick recap of what happened today
Primer on DeepSeek
Winners and losers in the AI ecosystem
Should you be buying Semis on this dip?
Catalysts from here & what to expect this week from META, MSFT, and GOOG
Part 1. Quick recap of what happened today
AI stocks experienced the worst nightmare today. 😭
By AI stocks, I meant the AI infrastructure companies in the semiconductor and networking equipment supply chain, such as:
NVDA (GPUs suppliers) -17% 📉
AVGO (Custom ASIC and networking components) -17% 📉
CRDO (networking components) -31% 📉
ANET (high speed switch) -22% 📉
TSMC (manufactures the chips above) -13% 📉
In aggregate, SOX (the semiconductor sector index) -10% today.
On the one hand, you saw hyperscalers stock suffer much less (MSFT down only 2%, GOOG down 4%), and META even up 2% (we will explain why).
Why did this happen?
Over the weekend, a Chinese company DeepSeek claimed to have developed an open source model competitive with ChatGPT, developed by OpenAI.
But this is not even the most shocking part.
The most shocking part is that according to its technical report,
“DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. Assuming the rental price of the H800 GPU is $2 per GPU hour, our total training costs amount to only $5.576M.”
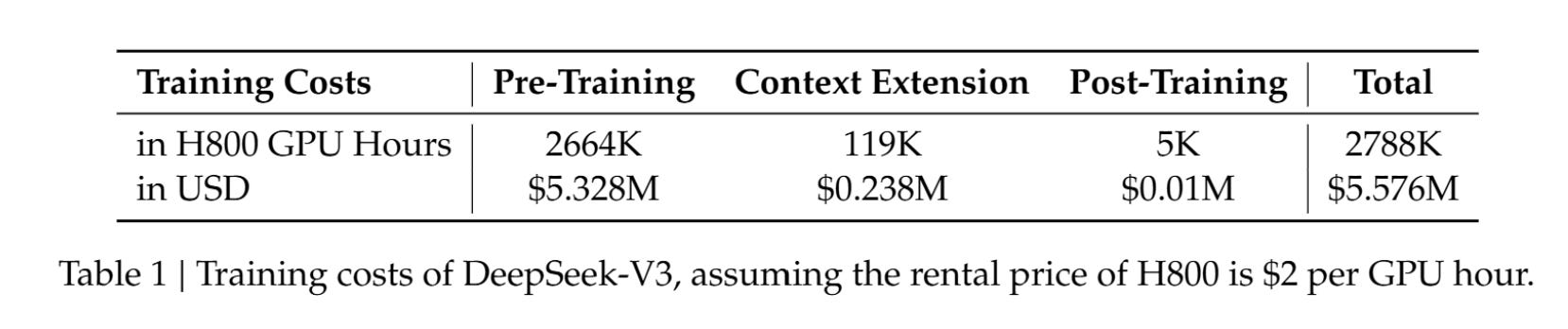
Why is this significant? DeepSeek’s total training cost is only $5.6M, when the likes of Google, Meta are spending billions of dollars in capex.
In addition, DeepSeek doesn’t even have access to the best GPUs available. Hopper is the current selling GPU architecture designed by NVDA. Hyperscalers today train their large language models using NVDA’s H200, today’s best GPU available before Blackwell’s planned mass shipment early this year.
On the other hand, Chinese companies face many more obstacles to develop their large language model, because compute power is a huge constraint. Back in 2022, the Biden administration restricted NVDA from selling the most advanced GPUs to China, with the goal to prevent China from making progress in AI development. NVDA tweaked its GPUs to sell to China as H800. Those H800s are a downgraded version of the regular H100 and H200 GPUs. They are less performant in two ways: 1) less powerful computing capabilities and 2) lower chip-chip data transfer rates.
The average selling price for H800 is in the thousands of dollars range, whereas each H200 is easily multiples of that (in the $30K range).
The fact that DeepSeek is able to develop a competitive large language model without pouring all the money into expensive and best performing GPUs is concerning for those selling these GPUs, custom ASICs, networking components, or high-bandwidth memory.
If you can spend only 1/30 of what you are spending today in AI infra (semis and networking equipment) but still get the best large language model, why bother?
Part 2. Primer on DeepSeek
On DeepSeek, there are many question marks. What is this company out of nowhere? Who funded this? What is the company’s future plan? Any implications on the geopolitical tension? For that, I will refer you to this interview conducted with the DeepSeek founder back in July 2024, and maybe we will write a more on this later.
For this article’s purpose, the most important question in my opinion is how was DeepSeek able to achieve such efficiency?
There are many reasons, including the Mixture-of-Experts model, Distillation process, mixed-precision training using FP8, and the Group Relative Policy Optimization (GRPO) reinforcement learning framework.
Mixture-of-Experts: this unique architecture combines numerous smaller models and leverages these specialized smaller models to handle different data aspects by dynamically selecting the most relevant expert for each input.
Distillation process: you can think of distillation as a teaching relationship, where the “student” model (small) learns from “teacher” model (large)’s outputs. This simulates a process of knowledge transfer. In the case of DeepSeek, it used the reasoning data generated by DeepSeek-R1 and fine-tuned several dense models that are open sourced today, including LLaMA8B and 70B, and Qwen 1.5, 7, 14, and 32B models.
Mixed precision training using FP8: ChatGPT and Gemini use floating point numbers to process and store data during model training. Most use FP32 as it provides very high precision, but the drawbacks are also clear. The more precise it is, the more memory and computing power is required. To solve this challenge, DeepSeek designed a system to use FP8 when it can, and only use FP32 when it’s a must, hence why it’s called mixed precision training. This brings down the total requirement for memory and computing power.
Group Relative Policy Optimization reinforcement learning framework: DeepSeek also introduced the GRPO, a variant reinforcement learning algorithm of Proximal Policy Optimization (PPO). GRPO enhances the existing learning algorithm by forgoing the critic model and instead estimating the baseline from group scores, which significantly reduced training resources.
Interestingly, even though DeepSeek claims they only spend 2 months and less than $6M in training their models, it’s worth noting that the Distillation process mentioned above suggests the upfront investments made by META and the likes in developing LLaMA are just as critical. So despite the technological advancement and efficiency gains made by DeepSeek, I wouldn’t simply use $6M as the “total training cost” for building a solid model from scratch.
Part 3. Winners and losers
First back to why META was up today
META also has an open source model called Llama. The success of DeepSeek’s model validates META’s open-source thesis, which is to encourage developers worldwide to accelerate innovation and improvement. The continued improvement in these open source models could give META and its customers advantage over closed source peers such as OpenAI and Gemini.
Gemini, OpenAI and other LLM competitors: Negative near term
The fact that DeepSeek has a much lower compute cost but a comparable performance means they can also offer much cheaper API for developers. For example, API pricing is $0.55/M input and $2.19/M output token, which is about 30x cheaper than what OpenAI is offering today. DeepSeek is also relying mostly on reinforcement learning vs supervised fine-tuning, which reduces the cost from data collection and data labeling.
In order to stay competitive, OpenAI will have to lower its pricing to retain customers, which doesn’t bode well for margins and free cash flow.
Software ecosystem: positive
Compute has been a huge constraint for application developers, the cost to train a large language model is elevated because of the expensive price tag of a GPU. As a result, the cost to develop applications by renting GPUs is also high.
As compute cost gets more commoditized, just like every technology innovation in history, it will lead to more applications, more use cases and as a result encourage more customer demand. The software companies will be able to harvest their existing data, customer relationships and leverage cheaper compute & hardware to provide better, smarter software solutions to customers at much better unit economics.
Net net, I view the DeepSeek news a positive for software companies as the pie will get much bigger.
AI Semiconductor companies?
The obvious answer is negative, given the commoditization of compute cost. But I think the long-term implication is more complex than that.
Part 4. Should you be buying Semis on this dip?
The short answer is not right now.
First thing first, I think the market is wrong today. When market sees something it doesn’t quite understand, they always “shoot first, ask questions later.” I view today’s stock reaction as an overreaction. After all, META last week just announced the plan to spend $65B in AI capex in 2025. Near term, investments in AI semiconductor and AI infrastructure will not stop.
Personally I hold the view that in the long run, compute power is still critical. Even though unit pricing might be lower (we might see GPU pricing going back to $5000 from $40K today, and NVDA Gross Margin retrace back to high 50s, low 60s from mid 70s today), but the pie will get bigger.
Ever heard of Jevons Paradox?
It simply means that when technological advancement makes a resource more efficient to use and reduces the cost of it, the overall demand increases will cause overall consumption of such resource to rise.
To me, this applies to high performance compute as more applications will be developed and there will be more demand for compute in aggregate.
However, I don’t think right now is the best time to buy the dip, unless you are patient enough.
I personally think these AI semiconductor companies will be in the penalty box for a while for two reasons.
There is no clear catalyst for the semiconductor stocks to move higher. META capex is well previewed. Mark Zuckerberg last week already guided capex to be $65B for 2025. So when they do report earnings, there is likely no upside surprise to capex, and therefore no incremental upside for AI semis and networking equipment’s revenue.
Another reason is why bother? Based on our discussion above, it’s very clear that we are going to see a shift in the value chain in the AI ecosystem. At first, the constraint is in compute, hence the compute suppliers gets the most value (that’s why NVDA is able to get a higher margin than its customers even though historically semiconductor companies have a much lower gross margin on average). However, as time goes by and as compute gets cheaper, more value will move to the application layer aka the software companies. If you are a tech investor, where do you want to put your investment money? I think the answer is quite obvious.
Sure, you might get a bounce here and there in semis, but the existential risk remains an overhang to the stock.
Part 5. Catalysts from here & what to expect this week from META, MSFT, GOOG
I think the most near-term catalysts from here are the META and MSFT earnings this week and GOOG earnings next week. One important metric is capex guidance, but more importantly, the tone of the management teams.
I suspect the Wall Street analysts will grill CEOs and CFOs on their capex plans.
“If DeepSeek is spending only couple percentage of what you are spending, is there some way you can optimize your capex investment? How do you think about your return on investment?”
These large public companies need to deliver solid financial numbers including return on investment (we discuss this more in detail here).
I doubt the CEOs will just go on stage and be super bullish on spending. They need to answer to their shareholders. The answer won’t be so great for their suppliers.
However, this doesn’t necessarily mean that their capex will fall off a cliff. I expect them to keep growing their AI capex spending, but at a lower growth rate. After all, even if you can lower cost by optimizing your large language model’s architecture, more compute is still a nice icing on the cake!
In fact, during an interview with the DeepSeek founder in July 2024, he mentioned that compute is still a constraint.
I expect earnings in the coming 2 weeks won’t settle the debate and I expect these semis companies to be in the penalty box for the next 2 quarters. NVDA’s GTC event could boost the stock somewhat, but it will all come down to their earnings results for this quarter (reporting earnings in mid Feb) and next quarter (early summer).
We know that Blackwell ramp is experiencing some supply chain challenges, so results likely won’t be too stellar. So we shall see!
Never a dull moment in tech investing.
If you have enjoyed reading this article, please consider liking, restacking, or sharing with your friends! Your engagement is the biggest support. ❤️
If you are interested in reading more:
Company primers with in-depth fundamental analysis and valuation framework:
Directory by ticker